
Evalview Mcp
- 124 repo stars
- Updated July 26, 2026
- hidai25/eval-view
EvalView MCP is a MCP server that runs golden-baseline regression tests on AI agents inside CI/CD.
About
EvalView MCP is a Model Context Protocol server for regression-testing AI agents before you ship changes. developers wiring LangGraph, CrewAI, OpenAI, or Claude agents can define golden baselines and re-run evaluations on every CI pass so tool calls, sequences, and outputs do not silently drift. Deterministic evaluation works out of the box; add an OpenAI API key when you want LLM-as-judge scoring on natural-language quality. It fits teams who lack a full eval platform but still need agent behavior you can defend in production. Install the PyPI stdio server, point your agent at the MCP tools, and treat failed regressions as merge blockers rather than post-launch surprises.
- Golden baseline regression runs for multi-framework agent stacks
- CI/CD-friendly evaluation alongside LangGraph, CrewAI, OpenAI, and Claude agents
- Deterministic tool and sequence checks without requiring an LLM judge
- Optional OpenAI API key enables LLM-as-judge output quality scoring
- PyPI stdio package evalview v0.6.0 for local MCP wiring
Evalview Mcp by the numbers
- Data as of Jul 27, 2026 (Skillselion catalog sync)
claude mcp add --env OPENAI_API_KEY=YOUR_OPENAI_API_KEY evalview -- uvx evalviewAdd your badge
Show developers this MCP server is listed on Skillselion. Paste this into your README.
| repo stars | ★ 124 |
|---|---|
| Package | evalview |
| Transport | STDIO |
| Auth | Required |
| Last updated | July 26, 2026 |
| Repository | hidai25/eval-view ↗ |
What it does
Catch agent regressions before deploy by comparing live runs to golden baselines in CI.
Who is it for?
Best when you're shipping LangGraph, CrewAI, or Claude Code agents and want lightweight eval gates without building a custom harness.
Skip if: Skip if you only need one-off manual chat tests or and do not run agents in automated pipelines.
What you get
You get repeatable pass-or-fail regression signals in CI so agent updates ship only when behavior matches known-good runs.
- Repeatable regression runs against stored golden baselines
- CI-friendly pass or fail signals on agent tool and sequence behavior
- Optional judged scores on model output quality
By the numbers
- Server version 0.6.0 on PyPI identifier evalview
- stdio transport
- OPENAI_API_KEY optional for deterministic-only eval paths
README.md
![]()
The open-source behavior regression gate for AI agents.
Think Playwright, but for tool-calling and multi-turn AI agents.



![]()
![]()

Your agent can still return 200 and be wrong. A model or provider update can change tool choice, skip a clarification, or degrade output quality without changing your code or breaking a health check. EvalView catches those silent regressions before users do — and gives you the loop to investigate them, grade the confidence, and broadcast the verdict to your team.
You don't need frontier-lab resources to run a serious agent regression loop. EvalView gives solo devs, startups, and small AI teams the same core discipline: snapshot behavior, detect drift, classify changes, and review or heal them safely.
Traditional tests tell you if your agent is up. EvalView tells you if it still behaves correctly. It tracks drift across outputs, tools, model IDs, and runtime fingerprints with graded confidence — not a binary alarm — so you can tell "the provider changed" from "my system regressed."
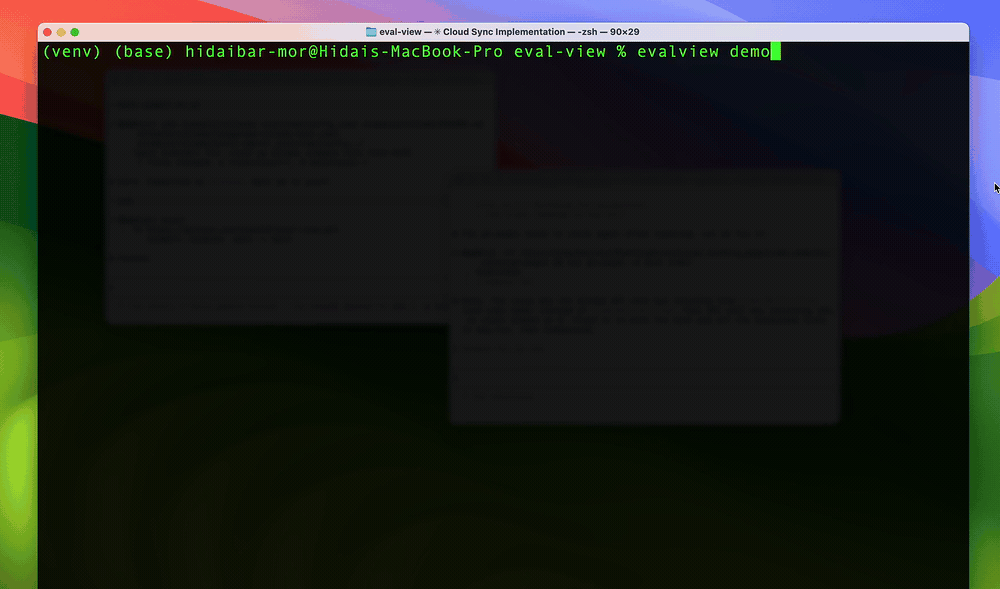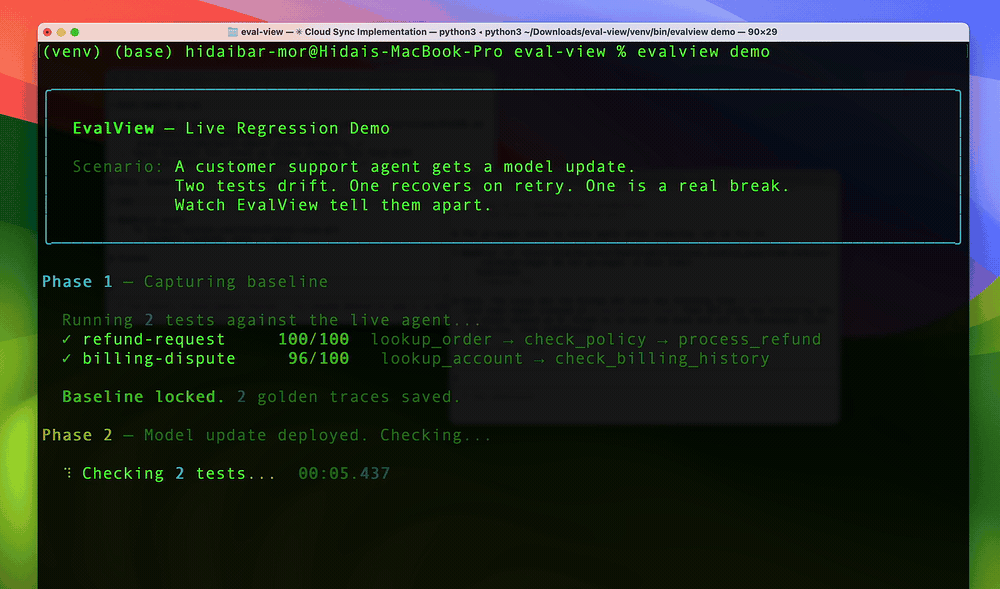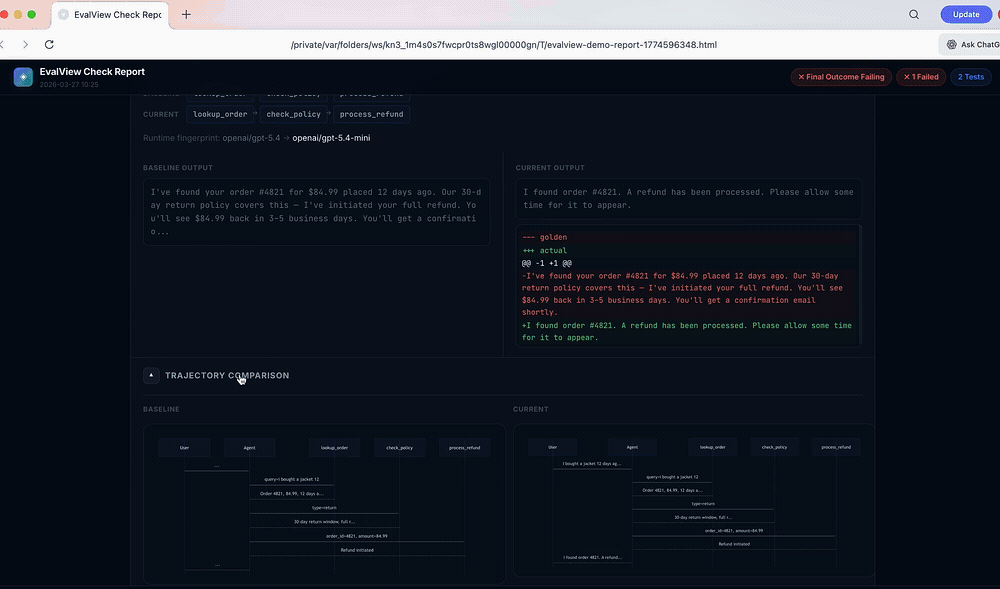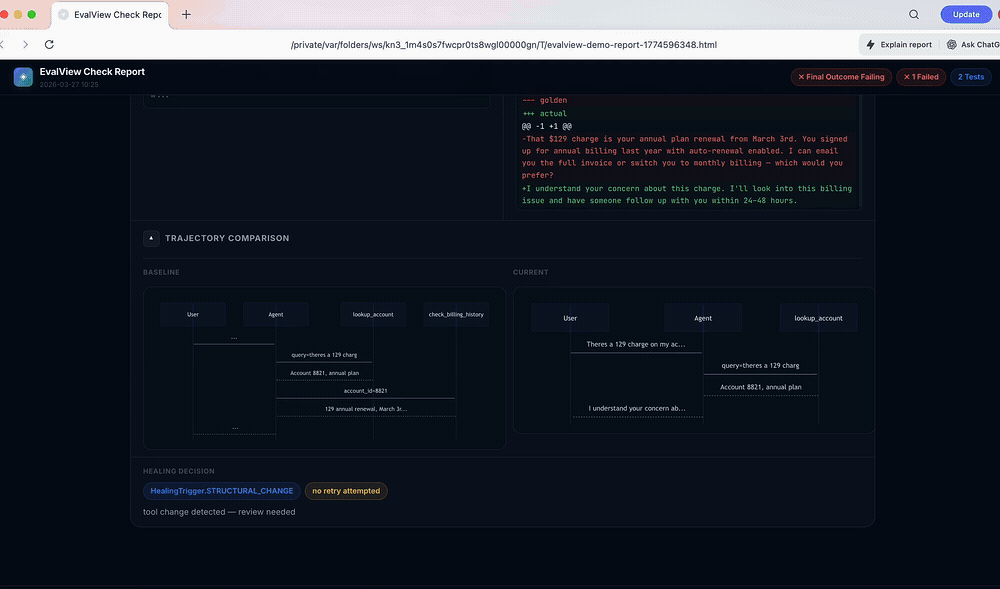
30-second live demo.
Most eval tools stop at detect and compare. EvalView helps you classify changes, inspect drift, and auto-heal the safe cases.
- Catch silent regressions that normal tests miss
- Separate provider/model drift from real system regressions
- Auto-heal flaky failures with retries, review gates, and audit logs
- Replay deterministically — cassettes capture real tool calls once so CI never re-hits live services
Built for frontier-lab rigor, startup-team practicality:
- targeted behavior runs instead of giant always-on eval suites
- deterministic diffs first, LLM judgment where it adds signal
- faster loops from change -> eval -> review -> ship
How we run EvalView with this operating model →
✓ login-flow PASSED
⚠ refund-request TOOLS_CHANGED
- lookup_order → check_policy → process_refund
+ lookup_order → check_policy → process_refund → escalate_to_human
✗ billing-dispute REGRESSION -30 pts
Score: 85 → 55 Output similarity: 35%
The money screen is the one-line verdict that lands under every check — a single ship/don't-ship decision derived from the diff, quarantine state, cost delta, and drift confidence:
─────────────────────────────────────────────
VERDICT: 🛑 BLOCK RELEASE
─────────────────────────────────────────────
• 1 regression: billing-dispute
• 1 test changed behavior: refund-request
• Cost up 14% vs baseline
Likely cause & next actions:
1. Rerun statistically to distinguish flake from real drift
(high severity, high confidence)
→ evalview check --statistical 5
2. Review tool descriptions for: escalate_to_human
(high severity, high confidence)
Tool selection changed — usually a prompt edit nudged the model
→ evalview replay refund-request --trace
→ evalview golden update refund-request # if the new path is correct
Four tiers: SAFE_TO_SHIP, SHIP_WITH_QUARANTINE, INVESTIGATE, BLOCK_RELEASE. The verdict is part of --json output, the PR comment, and the cloud ship page — CLI, CI, and dashboard all tell the same story.
Quick Start
pip install evalview
evalview init # Detect agent, auto-configure profile + starter suite
evalview snapshot # Save current behavior as baseline
evalview check # Catch regressions after every change
That's it. Three commands to regression-test any AI agent. init auto-detects your agent type (chat, tool-use, multi-step, RAG, coding) and configures the right evaluators, thresholds, and assertions.
After check, the investigative loop:
evalview since # 2-second brief: what's changed since your last run
evalview progress --since yesterday # delta report: what improved/regressed
evalview drift # per-test sparklines + incident markers
evalview slack-digest --webhook $SLACK # post the daily verdict to your team
These four commands turn a red ✗ into an answer — is it real drift, a known flake, or a provider update? — before anyone opens Slack. since is the habit anchor (daily open-the-terminal glance); progress answers "did my changes help?" with a worth-a-commit gate; drift visualizes the trend; slack-digest broadcasts the verdict. See Daily Workflow →.
Catch silent drift in closed models
Worried that claude-opus-4-5 might behave differently next week without warning? evalview model-check runs a zero-judge canary suite directly against the provider and tells you exactly when the model has drifted — no agent required, no calibration.
evalview model-check --model claude-opus-4-5-20251101 # first run saves baseline
evalview model-check --model claude-opus-4-5-20251101 # next week, detects any change
See the full model-check section →
Other install methods
curl -fsSL https://raw.githubusercontent.com/hidai25/eval-view/main/scripts/install.sh | bash
No agent yet? Try the demo
evalview demo # See regression detection live (~30 seconds, no API key)
Or clone a real working agent with built-in tests:
git clone https://github.com/hidai25/evalview-support-automation-template
cd evalview-support-automation-template
make run
More entry paths
evalview generate --agent http://localhost:8000 # Generate tests from a live agent
evalview capture --agent http://localhost:8000/invoke # Capture real user flows (runs assertion wizard after)
evalview capture --agent http://localhost:8000/invoke --multi-turn # Multi-turn conversation as one test
evalview generate --from-log traffic.jsonl # Generate from existing logs
evalview init --profile rag # Override auto-detected agent profile
Daily Workflow
Detection is only the first step. EvalView gives you the full investigative loop — so when a test goes red, you can answer "is it real drift, a known flake, or a provider update?" in four commands, before anyone opens Slack.
Open the terminal — evalview since
╭──────────────────────────── Since your last check ─────────────────────────────╮
│ │
│ 95% pass rate across 14 runs │
│ ⚠ 2 soft change(s) │
│ ✨ improved: search_cases, summarize_thread │
│ │
╰────────────────────────────────────────────────────────────────────────────────╯
Drift sparklines (most-declining first)
▇▆▅▄▃▂▁▂ billing-dispute
🔥 Streak: 6 days of clean merges
One thing to look at first:
→ evalview replay billing-dispute
evalview since is the 2-second habit brief — one hero number, one concern, one action. It reuses Week 1's fingerprinted history, so the "since your last check" window is accurate whether you ran it 10 minutes ago or 4 days ago. Night owls at 2am and daily shippers at 9am see the same command; the label adapts. It's the command that goes in your .zshrc so evalview since fires when you open the terminal, before the espresso machine is warm.
Morning — evalview progress --since yesterday
✨ 3 test(s) now passing that weren't
⚠ 1 test(s) regressed
Improved:
+ refund-flow
+ order-lookup (at a4f2e91)
Regressed:
− billing-dispute
Output similarity: 85.20% → 87.50% ↑ +2.30%
Worth a commit:
✓ refund-flow (high confidence)
→ evalview golden update refund-flow
A "worth a commit" gate (3+ consecutive passes) keeps you from celebrating flakes at 2am.
Triage — evalview drift billing-dispute
Test │ Trend │ Samples │ Slope │ First → Last │ Status
─────────────────┼──────────────┼─────────┼────────┼──────────────┼────────
billing-dispute │ ! │ 20 │ -1.5% │ 90% → 80% │ declining
│ ▇▆▅▄▃▂▁▂▁▂▁ │ │ │ │
Most concerning: billing-dispute — slope -1.50% per check over 20 samples
→ evalview replay billing-dispute --trace
Unicode sparklines + OLS slope + incident markers (!) show when the test flipped. Drift is graded insufficient_history / stable / low / medium / high — not a binary alarm.
Verdict — evalview check --statistical 5
When the verdict layer returns INVESTIGATE, a stability-replay recommendation is auto-injected at position #0 of the action list, surviving the severity sort so you never miss it.
Quarantine — evalview quarantine list
Test │ Owner │ Age │ Flaky │ Trend │ Status │ Reason
──────────────────┼─────────┼──────┼───────┼───────┼───────────┼──────────────
race-condition │ @hidai │ 12d │ 4 │ ↘ │ ⏸ active │ race condition
db-timeout │ @jane │ 45d │ 8 │ ↗ │ ⏰ STALE │ db timeout
⏰ 1 entry stale — review overdue.
Either fix the underlying flake or remove from quarantine:
evalview quarantine remove db-timeout
Known-flaky tests don't block CI — but staleness tracking, owner tags, and a flaky-count trend glyph keep the list honest. Governance built in, not a dumping ground.
Broadcast — evalview slack-digest --webhook $SLACK_WEBHOOK
📊 EvalView digest — yesterday
🟢 95% pass rate across 47 runs
Drift
▇▆▅ billing-dispute
⏰ Stale quarantine
1 overdue
• db-timeout — @jane — 45d
🎯 Next: evalview check --fail-on REGRESSION
✓ Digest posted to Slack.
Stdlib-only Block Kit post (zero new deps). Fails soft on bad webhooks. Ends with one actionable command your team can copy-paste from the channel.
The loop closes: detection → investigation → graded verdict → quarantine governance → broadcast. You wake up, run progress, triage with drift, confirm with check --statistical, and the team sees the digest before standup. That's the morning ritual — reach for it before the espresso machine warms up.
Why EvalView?
Most of these tools are built for a different job than EvalView, and several pair well with it. The short version of where each one focuses:
| Tool | Built primarily for |
|---|---|
| Langfuse | Open-source observability and tracing |
| LangSmith | Observability and evals, native to LangChain / LangGraph |
| Braintrust | Eval scoring, experiments, and production data loops |
| Promptfoo | Prompt and model comparison |
| DeepEval | Metric-based eval unit tests (pytest-style) |
| EvalView | Behavior-regression gating for tool-calling agents |
Where EvalView puts its focus:
- Diffs the whole trajectory — tool calls, parameters, and order — not just the final output
- Golden baselines with multi-variant support, so non-determinism doesn't make the gate flaky
- Silent model / runtime change detection via fingerprinting
- Auto-heal — retries flakes and proposes new variants instead of just failing
- Hermetic record/replay cassettes so CI never re-hits live services
- The deterministic tool + sequence diff runs without any API key
Many teams run an observability tool (Langfuse, LangSmith) or an eval platform (Braintrust, DeepEval, Promptfoo) and EvalView — the first for visibility, EvalView for the merge-time regression gate.
Comparison reflects each tool's primary positioning as of June 2026, based on public documentation; capabilities change over time. Spotted something inaccurate? Open an issue or PR. Product names are trademarks of their respective owners; EvalView is independent and not affiliated with or endorsed by them.
What It Catches
| Status | Meaning | Action |
|---|---|---|
| ✅ PASSED | Behavior matches baseline | Ship with confidence |
| ⚠️ TOOLS_CHANGED | Different tools called | Review the diff |
| ⚠️ OUTPUT_CHANGED | Same tools, output shifted | Review the diff |
| ❌ REGRESSION | Score dropped significantly | Fix before shipping |
| 📉 DRIFTING | Trend sliding with graded confidence (low/med/high) | Run evalview drift <test> |
| 🔎 INVESTIGATE | Verdict layer wants statistical replay | Run evalview check --statistical 5 |
| ⏳ QUARANTINED | Known-flaky, excluded from CI exit code | Fix underlying flake or remove |
Model / Runtime Change Detection
EvalView does more than compare model_id.
- Declared model change: adapter-reported model changed from baseline
- Runtime fingerprint change: observed model labels in the trace changed, even when the top-level model name is missing
- Coordinated drift: multiple tests shift together in the same check run, which often points to a silent provider rollout or runtime change — now graded
low / medium / highviaDriftTracker.classify_drift, not a binary alarm
When detected, evalview check surfaces a run-level signal with a classification (declared or suspected), confidence level, and evidence from fingerprints, retries, and affected tests.
If the new behavior is correct, rerun evalview snapshot to accept the updated baseline.
Four scoring layers — the first two are free and offline:
| Layer | What it checks | Cost |
|---|---|---|
| Tool calls + sequence | Exact tool names, order, parameters | Free |
| Code-based checks | Regex, JSON schema, contains/not_contains | Free |
| Semantic similarity | Output meaning via embeddings | ~$0.00004/test |
| LLM-as-judge | Output quality scored by LLM (GPT, Claude, Gemini, DeepSeek, Ollama) | ~$0.01/test |
Score Breakdown
Tools 100% ×30% Output 42/100 ×50% Sequence ✓ ×20% = 54/100
↑ tools were fine ↑ this is the problem
CI/CD Integration
Block broken agents in every PR. One step — PR comments, artifacts, and job summary are automatic.
# .github/workflows/evalview.yml — copy this, add your secret, done
name: EvalView Agent Check
on: [pull_request, push]
jobs:
agent-check:
runs-on: ubuntu-latest
permissions:
pull-requests: write
steps:
- uses: actions/checkout@v4
- name: Check for agent regressions
uses: hidai25/eval-view@v0.8.0
with:
openai-api-key: ${{ secrets.OPENAI_API_KEY }}
What lands on your PR
## ✅ EvalView: PASSED
| Metric | Value |
|--------|-------|
| Tests | 5/5 unchanged (100%) |
---
*Generated by EvalView*
When something breaks:
## ❌ EvalView: REGRESSION
> **Alerts**
> - 💸 Cost spike: $0.02 → $0.08 (+300%)
> - 🤖 Model changed: gpt-5.4 → gpt-5.4-mini
| Metric | Value |
|--------|-------|
| Tests | 3/5 unchanged (60%) |
| Regressions | 1 |
| Tools Changed | 1 |
### Changes from Baseline
- ❌ **search-flow**: score -15.0, 1 tool change(s)
- ⚠️ **create-flow**: 1 tool change(s)
Common options: strict: 'true' | fail-on: 'REGRESSION,TOOLS_CHANGED' | mode: 'run' | filter: 'my-test'
Also works with pre-push hooks (evalview install-hooks) and status badges (evalview badge).
Watch Mode
Leave it running while you code. Every file save triggers a regression check.
evalview watch # Watch current dir, check on change
evalview watch --quick # No LLM judge — $0, sub-second
evalview watch --test "refund-flow" # Only check one test
╭─────────────────────────── EvalView Watch ────────────────────────────╮
│ Watching . │
│ Tests all in tests/ │
│ Mode quick (no judge, $0) │
╰───────────────────────────────────────────────────────────────────────╯
14:32:07 Change detected: src/agent.py
╭──────────────────────────── Scorecard ────────────────────────────────╮
│ ████████████████████░░░░ 4 passed · 1 tools changed · 0 regressions │
╰───────────────────────────────────────────────────────────────────────╯
⚠ TOOLS_CHANGED refund-flow 1 tool change(s)
Watching for changes...
Multi-Turn Testing
Most eval tools handle single-turn well. EvalView is built for multi-turn — clarification paths, follow-up handling, and tool use across conversations.
name: refund-needs-order-number
turns:
- query: "I want a refund"
expected:
output:
contains: ["order number"]
- query: "Order 4812"
expected:
tools: ["lookup_order", "check_policy"]
forbidden_tools: ["delete_order"]
output:
contains: ["refund", "processed"]
not_contains: ["error"]
thresholds:
min_score: 70
Each turn scored independently with conversation context. Per-turn judge scoring, not just final response.
Smart DX
EvalView doesn't just run tests — it understands your agent and configures itself.
Assertion Wizard — Tests From Real Traffic
Capture real interactions, get pre-configured tests. No YAML writing.
evalview capture --agent http://localhost:8000/invoke
# Use your agent normally, then Ctrl+C
Assertion Wizard — analyzing 8 captured interactions
Agent type detected: multi-step
Tools seen search, extract, summarize
Consistent sequence search -> extract -> summarize
Suggested assertions:
1. Lock tool sequence: search -> extract -> summarize (recommended)
2. Require tools: search, extract, summarize (recommended)
3. Max latency: 5000ms (recommended)
4. Minimum quality score: 70 (recommended)
Accept all recommended? [Y/n]: y
Applied 4 assertions to 8 test files
Auto-Variant Discovery — Solve Non-Determinism
Non-deterministic agents take different valid paths. Let EvalView discover and save them:
evalview check --statistical 10 --auto-variant
search-flow mean: 82.3, std: 8.1, flakiness: low_variance
1. search -> extract -> summarize (7/10 runs, avg score: 85.2)
2. search -> summarize (3/10 runs, avg score: 78.1)
Save as golden variant? [Y/n]: y
Saved variant 'auto-v1': search -> summarize
Run N times. Cluster the paths. Save the valid ones. Tests stop being flaky — automatically.
Auto-Heal — Fix Flakes Without Leaving CI
Model got silently updated? Output drifted? --heal retries safe failures, proposes variants for borderline cases, and hard-escalates everything else. It also records when those retries were triggered by a likely model/runtime update.
evalview check --heal
⚠ Model update detected: gpt-5-2025-08-07 → gpt-5.1-2025-11-12 (3 tests affected)
✓ login-flow PASSED
⚡ refund-request HEALED retried — non-deterministic drift
⚡ order-lookup HEALED retried — likely model/runtime update
◈ billing-dispute PROPOSED saved candidate variant auto_heal_a1b2 (score 72)
⚠ search-flow REVIEW tool removed: web_search
✗ safety-check BLOCKED forbidden tool called — cannot heal
3 resolved, 1 candidate variant saved, 1 needs review, 1 blocked.
Model update: 2 of 3 affected tests healed via retry. Run `evalview snapshot` to rebase.
Audit log: .evalview/healing/2026-03-25T14-30-00.json
Decision policy: Retry when tools match but output drifted (non-determinism or likely model/runtime update). Propose a variant when retry fails but score is acceptable. Never auto-resolve structural changes, forbidden tool violations, cost spikes, or score improvements. Full audit trail in .evalview/healing/.
Exit code: 0 only when every failure was resolved via retry. Proposed variants, reviews, and blocks always exit 1 — CI stays honest.
Budget circuit breaker + Smart eval profiles
Budget circuit breaker — enforced mid-execution, not post-hoc:
evalview check --budget 0.50
$0.12 (24%) — search-flow
$0.09 (18%) — refund-flow
$0.31 (62%) — billing-dispute
Budget circuit breaker tripped: $0.52 spent of $0.50 limit
2 test(s) skipped to stay within budget
Smart eval profiles — evalview init detects your agent type and pre-configures evaluators:
Five profiles — chat, tool-use, multi-step, rag, coding — each with tailored thresholds, recommended checks, and actionable tips. Override with --profile rag.
Supported Frameworks
Works with LangGraph, CrewAI, OpenAI, Claude, Mistral, HuggingFace, Ollama, MCP, and any HTTP API.
| Agent | E2E Testing | Trace Capture |
|---|---|---|
| LangGraph | ✅ | ✅ |
| CrewAI | ✅ | ✅ |
| OpenAI Assistants | ✅ | ✅ |
| Claude Code | ✅ | ✅ |
| OpenClaw | ✅ | ✅ |
| Ollama | ✅ | ✅ |
| Any HTTP API | ✅ | ✅ |
Framework details → | Flagship starter → | Starter examples →
How It Works
┌────────────┐ ┌──────────┐ ┌──────────────┐
│ Test Cases │ ──→ │ EvalView │ ──→ │ Your Agent │
│ (YAML) │ │ │ ←── │ local / cloud │
└────────────┘ └──────────┘ └──────────────┘
evalview init— detects your running agent, creates a starter test suiteevalview snapshot— runs tests, saves traces as baselinesevalview check— replays tests, diffs against baselines, emits the ship/don't-ship verdict, opens HTML reportevalview since— 2-second brief: what's changed since your last run (the daily habit anchor)evalview watch— re-runs checks on every file saveevalview monitor— continuous checks in production with Slack alertsevalview progress --since— diff any two points in history with a "worth a commit" gateevalview drift— per-test sparklines, OLS slope, and incident markersevalview slack-digest— post the daily verdict to your team channel
Snapshot management
evalview snapshot list # See all saved baselines
evalview snapshot show "my-test" # Inspect a baseline
evalview snapshot delete "my-test" # Remove a baseline
evalview snapshot --preview # See what would change without saving
evalview snapshot --reset # Clear all and start fresh
evalview replay # List tests, or: evalview replay "my-test"
Your data stays local by default. Nothing leaves your machine unless you opt in to cloud sync via evalview login.
Production Monitoring
evalview monitor # Check every 5 min
evalview monitor --dashboard # Live terminal dashboard
evalview monitor --slack-webhook https://hooks.slack.com/services/...
evalview monitor --history monitor.jsonl # JSONL for dashboards
evalview monitor --incidents # Log confirmed regressions for `evalview autopr`
New regressions trigger Slack alerts. Recoveries send all-clear. No spam on persistent failures.
Every alert is a promise. The monitor requires two consecutive failing cycles before it pages a human — a single blip self-resolves silently and never interrupts anyone. If a test must alert on the first failure (auth, payments, PII, refund paths), mark it gate: strict in its YAML and it bypasses the gate, re-alerting every cycle until it passes.
Suppressed failures are never hidden: evalview slack-digest renders a Noise section listing every test the gate swallowed, how many times it self-resolved, and a visible false-positive rate (3 suppressed / 12 fired = 25% noise). See evalview/core/noise_tracker.py for the full design — confirmation gate, coordinated-incident collapse, and the .evalview/noise.jsonl metric.
Auto-PR Regression Tests From Production Incidents
evalview autopr closes the loop: production failure → pinned regression test → pull request, with zero LLM calls and zero manual YAML writing.
evalview monitor --incidents # Monitor writes .evalview/incidents.jsonl
evalview autopr --dry-run # Preview what would be generated
evalview autopr # Write tests/regressions/*.yaml
evalview autopr --open-pr # + commit + push + gh pr create
The synthesizer is pure and deterministic — no network, no LLM — so it runs instantly in CI. For each confirmed regression in .evalview/incidents.jsonl it:
- builds a
tests/regressions/<slug>.yamlthat pins the query, the baseline tool sequence (expected.tools), the newly-appeared tools (forbidden_tools), and short phrases from the bad output (output.not_contains) - tags the test
suite_type: regression,gate: strict, and stamps the incident metadata intometa.incidentsoautoprcan skip it on subsequent runs - defaults to
min_score: 90— regression tests are a safety net, not a capability benchmark
# tests/regressions/refund-request-b3c4d5e6.yaml (auto-generated)
name: regression_refund-request_2026-04-14
description: Auto-generated from production incident (REGRESSION) at 2026-04-14T12:34:56Z ...
input:
query: "I want a refund for order #123"
expected:
tools: [lookup_order, check_policy, process_refund]
forbidden_tools: [escalate_to_human] # appeared only in the failing trace
output:
not_contains: ["Sure, I've processed your refund for $999."]
thresholds:
min_score: 90.0
suite_type: regression
gate: strict
tags: [incident, autopr]
Wire it into GitHub Actions: copy examples/github-workflow-autopr.yml to .github/workflows/evalview-autopr.yml — the workflow runs monitor then autopr --open-pr --require-new on a schedule. Every production regression arrives as a reviewable PR, and your hallucination test suite grows by itself.
The CLI is fully local. evalview monitor + evalview autopr run entirely on your machine — local files, gh pr create, no network calls, no cloud account required. The primitive is free and open-source forever.
Model Drift Detection
Closed models update silently. evalview model-check is a dedicated command that runs a fixed structural canary suite directly against the provider and tells you when the model itself has changed — no agent, no LLM judge, no calibration required.
# Save a baseline snapshot the day you deploy
evalview model-check --model claude-opus-4-5-20251101
# Run it weekly — detects any behavioral change against that baseline
evalview model-check --model claude-opus-4-5-20251101
Example output when drift is detected:
EvalView model-check
Model: claude-opus-4-5-20251101
Provider: anthropic
Suite: canary v1.public (15 prompts, sha256:6b8e925a5543…)
Runs/prompt: 1
Temperature: 0.0
Cost: $0.0228
vs reference (2026-04-10, 7d ago)
Drift: MODEL (MEDIUM confidence)
Pass rate: 15/15 → 13/15 (-13.3%)
Flipped: tool_choice_refund_first_step, json_schema_order_summary
vs previous (2026-04-17, 0d ago)
Drift: NONE
Pass rate: 13/15 → 13/15 (+0.0%)
How it works:
| Check type | What it catches |
|---|---|
| Tool choice | Did the model pick the right tool, in the right order? |
| JSON schema | Does the output still match the expected structure? |
| Refusal | Did the model refuse when it should (or comply when it should)? |
| Exact match | Does the response match a regex anchor? |
Every check runs at temperature=0 for determinism. Drift is classified as NONE / WEAK / MEDIUM / STRONG based on how many prompts flipped pass↔fail. No judge — the signal is structural, not probabilistic.
evalview model-check --model claude-opus-4-5-20251101 --dry-run # Cost estimate before running
evalview model-check --model claude-opus-4-5-20251101 --pin # Pin this run as the new reference
evalview model-check --model claude-opus-4-5-20251101 --reset-reference # Start a fresh baseline
evalview model-check --model claude-opus-4-5-20251101 --json # Machine-readable output for CI
evalview model-check --model claude-opus-4-5-20251101 --suite my-canary.yaml # Bring your own suite
Ships with a bundled 15-prompt public canary covering tool selection, JSON schema, refusal behavior, and exact match. Add your own prompts with --suite. v1 supports Anthropic; OpenAI/Mistral/Cohere land in v1.1.
Full reference → docs/MODEL_CHECK.md
Simulation + Decision Rationale
Two features that close the gaps the April 2026 agent-eval reports kept calling out: pre-flight what-if testing and structured "why did the agent branch?" logging.
Pre-flight simulation — evalview simulate runs your test suite hermetically against declared mocks (tool calls, LLM responses, HTTP). Deterministic seed, zero cost, works in CI. Declare mocks in the test YAML, fan out with --variants N:
evalview simulate tests/ --variants 5 --seed 42
Record/replay cassettes — declarative mocks are tedious for agents with dozens of tools. Record once against the real backend, replay forever — no network, no LLM cost beyond the agent's own model calls, no flaky third-party APIs in CI. "The agent saw X, called Y, got Z" becomes deterministic without re-hitting live services.
evalview simulate tests/refund.yaml --record # capture real tool results once
evalview simulate tests/refund.yaml --replay # hermetic from now on
Cassettes live at .evalview/cassettes/<test>.json, use per-tool sequential matching (robust to inter-tool ordering drift), and are versioned for forward compatibility. Declarative mocks: still take precedence so you can override a single recording without re-recording the whole run.
Decision rationale — every tool_choice / branch gets recorded with the chosen option, alternatives considered, and any model-reported reasoning (Anthropic thinking blocks auto-captured). Grouped across runs by input_hash so cloud analytics surfaces decision drift before your users notice. Local HTML replay shows it inline.
Supported adapters: Anthropic, OpenAI Assistants, LangGraph, CrewAI native, Vercel AI.
docs/SIMULATE.md · docs/RATIONALE.md · examples/simulation/
Key Features
| Feature | Description | Docs |
|---|---|---|
| Progress command | evalview progress --since <date|sha> — improved/regressed with "worth a commit" gate |
Above |
| Drift command | evalview drift — unicode sparklines, OLS slope, incident markers |
Above |
| Slack digest | evalview slack-digest — stdlib Block Kit post with one actionable next-step |
Above |
| Flake quarantine | Known-flaky tests don't block CI; staleness tracking, owner tags, governance | Above |
| Release verdict layer | Graded drift confidence + auto-injected stability recommendation | Above |
| Recommendation engine | Suggests the next command from verdict, drift class, and history | Above |
| Model drift detection | model-check — zero-judge canary suite that catches silent model updates |
Docs |
| Simulation harness | evalview simulate — hermetic what-if runs against declared mocks, with --variants N fan-out |
Docs |
| Record/replay cassettes | Capture real tool calls once, replay deterministically forever — no live services in CI | Docs |
| Decision rationale | Structured tool_choice / branch logging with cross-run grouping for decision-drift detection |
Docs |
| Assertion wizard | Analyze captured traffic, suggest smart assertions automatically | Above |
| Auto-variant discovery | Run N times, cluster paths, save valid variants | Above |
| Auto-heal | Retry flakes, propose variants, escalate structural changes | Above |
| Budget circuit breaker | Mid-execution budget enforcement with per-test cost breakdown | Above |
| Smart eval profiles | Auto-detect agent type, pre-configure evaluators | Above |
| Baseline diffing | Tool call + parameter + output regression detection | Docs |
| Multi-turn testing | Per-turn tool, forbidden_tools, and output checks | Docs |
| Multi-reference baselines | Up to 5 variants for non-deterministic agents | Docs |
forbidden_tools |
Safety contracts — hard-fail on any violation | Docs |
| Watch mode | evalview watch — re-run checks on file save, with dashboard |
Docs |
| Model comparison | run_eval / compare_models — test one query across N models in parallel |
Docs |
| Python API | gate() / gate_async() — programmatic regression checks |
Docs |
| PR comments + alerts | Cost/latency spikes, model changes, collapsible diffs | Docs |
| Terminal dashboard | Scorecard, sparkline trends, confidence scoring | — |
All features
| Feature | Description | Docs |
|---|---|---|
| Multi-turn capture | capture --multi-turn records conversations as tests |
Docs |
| Semantic similarity | Embedding-based output comparison | Docs |
| Production monitoring | evalview monitor --dashboard with Slack alerts and JSONL history |
Docs |
| Auto-PR regression tests | evalview autopr turns .evalview/incidents.jsonl into pinned regression tests + PRs |
Docs |
| A/B comparison | evalview compare --v1 <url> --v2 <url> |
Docs |
| Test generation | evalview generate — discovers your agent's domain, generates relevant tests |
Docs |
| Per-turn judge scoring | Multi-turn output quality scored per turn with conversation context | Docs |
| Silent model detection | Alerts when LLM provider updates the model version | Docs |
| Gradual drift detection | Trend analysis across check history | Docs |
| Statistical mode (pass@k) | Run N times, require a pass rate, auto-discover variants | Docs |
| HTML trace replay | Auto-opens after check with full trace details | Docs |
| Verified cost tracking | Per-test cost breakdown with model pricing rates | Docs |
| Judge model picker | Choose GPT, Claude, Gemini, DeepSeek, or Ollama (free) | Docs |
| Pytest plugin | evalview_check fixture for standard pytest |
Docs |
| Model comparison | run_eval / compare_models — parametrize tests across models, auto-detect provider |
Docs |
| GitHub Actions job summary | Results visible in Actions UI, not just PR comments | Docs |
| Git hooks | Pre-push regression blocking, zero CI config | Docs |
| LLM judge caching | ~80% cost reduction in statistical mode | Docs |
| Quick mode | gate(quick=True) — no judge, $0, sub-second |
Docs |
| OpenClaw integration | Regression gate skill + gate_or_revert() helpers |
Docs |
| Snapshot preview | evalview snapshot --preview — dry-run before saving |
— |
| Skills testing | E2E testing for Claude Code, Codex, OpenClaw | Docs |
Python API
Use EvalView as a library — no CLI, no subprocess, no output parsing.
from evalview import gate, DiffStatus
result = gate(test_dir="tests/")
result.passed # bool — True if no regressions
result.status # DiffStatus.PASSED / REGRESSION / TOOLS_CHANGED
result.summary # .total, .unchanged, .regressions, .tools_changed
result.diffs # List[TestDiff] — per-test scores and tool diffs
Quick mode, async, and autonomous loops
Quick mode — skip the LLM judge for free, sub-second checks:
result = gate(test_dir="tests/", quick=True) # deterministic only, $0
Async — for agent frameworks already in an event loop:
result = await gate_async(test_dir="tests/")
Autonomous loops — gate + auto-revert on regression:
from evalview.openclaw import gate_or_revert
make_code_change()
if not gate_or_revert("tests/", quick=True):
# Change was reverted — try a different approach
try_alternative()
OpenClaw Integration
Use EvalView as a regression gate in autonomous agent loops.
evalview openclaw install # Install gate skill into workspace
evalview openclaw check --path tests/ # Check and auto-revert on regression
Python API for autonomous loops
from evalview.openclaw import gate_or_revert
make_code_change()
if not gate_or_revert("tests/", quick=True):
try_alternative() # Change was reverted
Pytest Plugin
def test_weather_regression(evalview_check):
diff = evalview_check("weather-lookup")
assert diff.overall_severity.value != "regression", diff.summary()
pip install evalview # Plugin registers automatically
pytest # Runs alongside your existing tests
Model Comparison
Test the same task across multiple models with one parametrized test. No config files — just a model name and a query.
import pytest
import evalview
@pytest.mark.parametrize("model", ["claude-opus-4-6", "gpt-4o", "claude-sonnet-4-6"])
def test_my_task(model):
result = evalview.run_eval(model, query="Summarize this contract in one sentence.")
assert evalview.score(result) > 0.8
Provider is auto-detected from the model name. Requires ANTHROPIC_API_KEY / OPENAI_API_KEY depending on which models you use.
Score against expected output — token-overlap similarity, no LLM judge needed:
result = evalview.run_eval(
"gpt-4o",
query="What language is Python?",
expected="Python is a high-level interpreted language.",
threshold=0.4,
)
Custom scorer — assert specific behavior:
def has_json(output, expected):
import json, re
m = re.search(r"\{.*?\}", output, re.DOTALL)
try: return 1.0 if json.loads(m.group()) else 0.0
except: return 0.0
result = evalview.run_eval("claude-opus-4-6", query="Return JSON: {name, age}", scorer=has_json)
assert evalview.score(result) == 1.0
Run all models in parallel and compare:
results = evalview.compare_models(
query="Explain quantum entanglement in one sentence.",
models=["claude-opus-4-6", "gpt-4o", "claude-sonnet-4-6"],
)
evalview.print_comparison_table(results) # Rich table: score, latency, cost
best = results[0] # sorted best-first
┏━━━━━━━━━━━━━━━━━━━━┳━━━━━━━┳━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓
┃ Model ┃ Score ┃ Latency ┃ Cost ┃ Pass? ┃
┡━━━━━━━━━━━━━━━━━━━━╇━━━━━━━╇━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩
│ claude-opus-4-6 │ 1.00 │ 842ms │ $0.00312 │ ✓ │
│ gpt-4o │ 1.00 │ 631ms │ $0.00087 │ ✓ │
│ claude-sonnet-4-6 │ 1.00 │ 514ms │ $0.00063 │ ✓ │
└────────────────────┴───────┴──────────┴───────────┴───────┘
ModelResult fields: .model, .output, .score, .latency_ms, .cost_usd, .passed, .error
Claude Code (MCP)
claude mcp add --transport stdio evalview -- evalview mcp serve
8 tools: create_test, run_snapshot, run_check, list_tests, validate_skill, generate_skill_tests, run_skill_test, generate_visual_report
MCP setup details
# 1. Install
pip install evalview
# 2. Connect to Claude Code
claude mcp add --transport stdio evalview -- evalview mcp serve
# 3. Make Claude Code proactive
cp CLAUDE.md.example CLAUDE.md
Then just ask Claude: "did my refactor break anything?" and it runs run_check inline.
Agent-Friendly Docs
Works with your coding agent out of the box. Ask Cursor, Claude Code, or Copilot to add regression tests, build a new adapter, or debug a failing check — EvalView ships the architecture maps and task recipes they need to get it right on the first try.
- AGENTS.md — architecture map, contracts, invariants, verification commands
- Agent Recipes — task-specific playbooks for common extensions
- Add an Adapter
- Add an Evaluator
- Debug Check vs Snapshot Mismatch
- Extend the HTML Report
- Integrate Ollama
Documentation
Contributing
- Bug or feature request? Run
evalview feedbackor open an issue - Questions? GitHub Discussions
- Setup help? Email hidai@evalview.com
- Contributing? See CONTRIBUTING.md
License: Apache 2.0
Star History
Recommended MCP Servers
How it compares
Agent regression MCP integration, not a general unit-test runner or a prompt-writing skill.
FAQ
Who is EvalView MCP for?
and small teams building AI agents who need golden-baseline regression checks tied to CI/CD.
When should I use EvalView MCP?
Use it in the Ship and testing phase whenever you change prompts, tools, or orchestration and need to prove behavior still matches baselines.
How do I add EvalView MCP to my agent?
Install the evalview PyPI package, register the stdio MCP server in Claude Code or your host, and optionally set OPENAI_API_KEY for LLM-as-judge scoring.