
Kb Retriever
Answer questions over a local mixed-format knowledge directory using hierarchical indexes and capped progressive retrieval—without loading whole PDFs or spreadsheets into context.
Overview
kb-retriever is an agent skill most often used in Build (also Idea research, Grow content) that answers questions over a local knowledge base via data_structure.md navigation and at most five progressive retrieval rounds
Install
npx skills add https://github.com/conardli/garden-skills --skill kb-retrieverWhat is this skill?
- Walks layered data_structure.md indexes to pick candidate files before full reads
- Learn-before-process gate: PDF and Excel require references/*.md plus recommended tools—not blind whole-file loads
- Hard cap of at most five retrieval rounds to bound context cost
- Answers with cited sources from local Markdown, PDF, Excel, and mixed directories
- Compat across claude-code, cursor, codex-cli, gemini-cli, and opencode-style agents
- Mandatory learn-before-process for PDF and Excel via references/*.md
Adoption & trust: 1.4k installs on skills.sh; 7.6k GitHub stars; 3/3 security scanners passed (skills.sh audits).
What problem does it solve?
Your agent either ignores local docs or loads huge PDFs and spreadsheets into context, blowing tokens and missing the right file.
Who is it for?
Builders maintaining a indexed local KB (data_structure.md trees) who want reliable Q&A in Claude Code, Cursor, or Codex without full-file ingestion.
Skip if: Teams needing live web search, multi-user hosted RAG with ACLs, or repos with no index hierarchy and no reference guides for binary formats.
When should I use this skill?
Questions must be answered from a local multi-format knowledge directory using data_structure.md indexes and bounded retrieval.
What do I get? / Deliverables
You get source-backed answers from indexed local files after bounded retrieval rounds, with PDF/Excel handled through the required reference guides and tools.
- Natural-language answers with sources
- Progressive retrieval trace within five rounds
- Tool-guided reads for PDF/Excel per reference docs
Recommended Skills
Journey fit
Spans multiple journey phases - primary shelf plus alternate fits below.
Build/agent-tooling is the canonical shelf because the skill wires retrieval behavior into how your coding agent navigates a personal or project knowledge base. Progressive index navigation and tool-bound PDF/Excel handling are agent-capability patterns, not generic doc authoring.
Where it fits
Trace competitor notes and PDF briefs through indexes instead of uploading entire decks.
Wire the retriever so implementation questions pull from internal architecture markdown and spreadsheets safely.
Answer onboarding questions from a mixed-format docs tree with explicit citations.
Draft lifecycle emails from indexed playbooks with five-round retrieval caps.
How it compares
Index-guided local retrieval skill—not a hosted vector DB SaaS or generic filesystem grep.
Common Questions / FAQ
Who is kb-retriever for?
Solo and indie builders who keep product, legal, and ops knowledge in a local folder tree and want agents to query it with progressive, source-cited retrieval.
When should I use kb-retriever?
Use it during Build agent-tooling when wiring doc-aware agents, in Idea research when mining indexed research folders, or in Grow content when drafting from local playbooks—whenever questions should hit data_structure.md first and stay within five retrieval rounds.
Is kb-retriever safe to install?
It reads local filesystem paths you designate; check Security Audits on this page and avoid pointing it at directories with secrets you do not want in agent context.
SKILL.md
READMESKILL.md - Kb Retriever
{ "name": "kb-retriever", "version": "1.0.0", "category": "Retrieval / Local Knowledge Base", "description": "Local knowledge-base retriever with progressive search. Navigates layered data_structure.md indexes, enforces learn-before-process for PDF and Excel, bounds retrieval to at most five rounds, and answers with sources.", "homepage": "https://github.com/ConardLi/garden-skills/tree/main/skills/kb-retriever", "compat": [ "claude-code", "claude-ai", "cursor", "codex-cli", "gemini-cli", "opencode" ] } # Kb Retriever Skill — Local Knowledge-Base Retriever > A skill for AI agents to efficiently answer questions over a **local, multi-format knowledge directory** using hierarchical index navigation and progressive retrieval — without ever loading whole files into context. [中文文档](./README.zh-CN.md) · [Back to collection root](../../README.md) 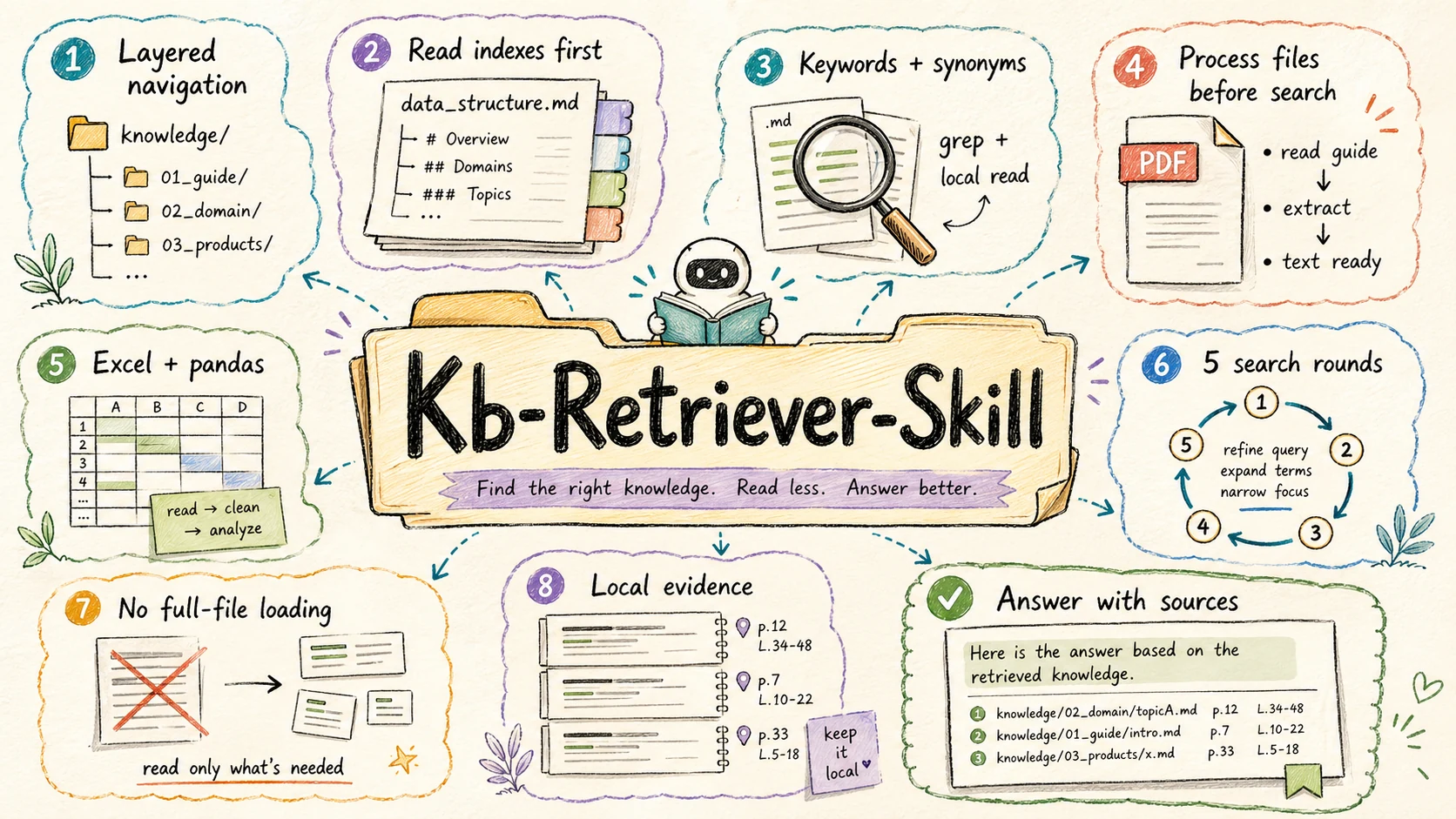 ## What it does Point the agent at a local directory full of mixed-format files (Markdown, PDF, Excel, …) and ask questions in natural language. The skill: 1. **Walks a hierarchical index** of `data_structure.md` files to figure out *which* files are likely to contain the answer. 2. **Forces a learn-before-process step** when it hits a PDF or Excel — it must read the corresponding `references/*.md` first and use the recommended tool, instead of blindly reading the whole file. 3. **Retrieves progressively** with `grep` + small windowed reads (offset/limit) instead of dumping entire files into context. 4. **Iterates up to 5 rounds**, narrowing keywords each round until it has enough evidence to answer. --- ## Core features - ✅ **Multi-format**: Markdown / text, PDF, Excel — extensible per file type. - ✅ **Hierarchical index**: each directory carries its own `data_structure.md`, forming an index tree the agent navigates. - ✅ **Progressive retrieval**: grep-first, windowed reads, never whole-file loads — keeps token usage low even on large corpora. - ✅ **Mandatory learning step**: PDF/Excel processing is gated on reading the right `references/*.md` first. - ✅ **Bounded iteration**: at most 5 retrieval rounds, with explicit termination conditions. --- ## Skill structure ``` skills/kb-retriever/ ├── SKILL.md Main skill (frontmatter name: kb-retriever) ├── README.md / README.zh-CN.md This document ├── references/ │ ├── pdf_reading.md How to handle PDFs (pdftotext / pdfplumber / pypdf) │ ├── excel_reading.md How to read Excel with pandas (nrows, dtype, etc.) │ └── excel_analysis.md How to filter / aggregate / derive metrics on Excel └── scripts/ └── convert_pdf_to_images.py Convert PDF pages to images when text extraction fails ``` --- ## Setting up your knowledge base This skill **does not ship a knowledge base** — you bring your own. Two ways to wire it up: ### Default location Put a `knowledge/` directory at the root of the workspace where you invoke the agent: ``` your-project/ ├── .claude/skills/ or .agents/skills/ │ └── kb-retriever/ ← this skill folder └── knowledge/ ← ← ← your knowledge base ├── data_structure.md (root-level index, see template below) ├── <domain-1>/ │ ├── data_structure.md │ └── ... └── <domain-2>/ └── ... ``` ### Custom location Tell the agent which path to use in your question, e.g. *"answer from `./docs`"* or *"my knowledge base is at `/data/kb`"*. The skill will use that path instead. If the default `knowledge/` does not exist and the user hasn't specified a path, the skill will ask rather than guess. ### `data_structure.md` template Each indexed directory should carry one of these: ```markdown # [Directory name] ## Purpose What this directory is for and when it should be searched. ## Files - file1.pdf — what it contains, time / version